-
#1 텍스트데이터를 엑셀, 워드클라우드로 만들기PYTHON/Python 업무 자동화 2024. 1. 2. 21:30
* https://www.yes24.com/Product/Goods/118396923 이 책을 보고 공부하였습니다.
IT 비전공자를 위한 파이썬 업무 자동화 (RPA) - 예스24
해도 해도 끝나지 않는 반복 업무... 어떻게 해결할 수 있을까요?상사의 지시, 고객사 대응, 메일 처리, 일정 문의, 정산 작업... 해도 해도 줄기는커녕 늘어나는 반복 업무. 매크로와 단축키 신공
www.yes24.com
주피터 노트북 코드 실행 후 셀 생성 : alt + enter
주피터 코드 실행 : shift + enter
Selenium 패키지에서 Webdriver 라이브러리를 가져옴, 파이썬으로 브라우저를 구동시키기 위한 작업 주피터 노트북은 하나의 라인을 셀이라고 함 ( 코드 셀 / 마크다운 셀 )
코드 셀 : 코드 구현
마크다운 셀 : 문서 제작할 때 사용
1. 인터넷에 있는 특정 단어와 관련된 기사의 제목 가져오기
2. 가져온 기사를 엑셀 한 시트로 만들기
3. 가져온 기사 제목을 모아서 워드클라우드로 제작
4. 제작된 이미지를 원하는 곳으로 전송import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium import webdriver from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager import pandas as pd from wordcloud import WordCloud, STOPWORDS def xl(): service = Service(executable_path = ChromeDriverManager().install()) # USB 장치 관련 기능을 비활성화 options = webdriver.ChromeOptions() options.add_experimental_option('excludeSwitches', ['enable-logging']) # 로깅 비활성화 driver = webdriver.Chrome(options=options) driver = webdriver.Chrome(service = service) time.sleep(1) # 네이버 접속 url = 'https://www.naver.com/' driver.get(url) time.sleep(1) # 원하는 키워드 검색 selector = '#query' greenbox = driver.find_element(By.CSS_SELECTOR, selector) greenbox.send_keys("반도체") selector = '#sform > fieldset > button' search_btn = driver.find_element(By.CSS_SELECTOR, selector) search_btn.click() # 뉴스 접속 selector = '#lnb > div.lnb_group > div > div.lnb_nav_area._nav_area_root > div > div.api_flicking_wrap._conveyer_root > div:nth-child(1) > a' new = driver.find_element(By.CSS_SELECTOR, selector) new.click() # 뉴스 탭에 나오는 기사들을 최신순으로 배열해 리스트 변수에 담는다 selector = '.list_news' # 클래스명이 'list_news'인 요소를 모두 가져와 변수에 저장 first_sel = driver.find_element(By.CSS_SELECTOR, selector) second_sel = first_sel.find_elements(By.TAG_NAME, "li") # first_sel에 담긴 요소 중 li 태그 요소를 다 가져옴 news_title_lists = [] # news_title_list라는 비어있는 리스트 변수에 기사 내용을 하나씩 저장 for i in second_sel: news_title_lists.append(i.text.replace("\n","")) #특수문자를 공백으로 교체 print("=" * 10 + "추출한 텍스트는?" + "=" * 10) print(news_title_lists) time.sleep(1) # 리스트 변수를 엑셀로 변환 df = pd.DataFrame(news_title_lists) # news_title_lists에 있는 데이터들을 pandas 데이터프레임으로 저장 df.to_excel('new.xlsx') time.sleep(1) # 리스트 변수의 본문들을 합쳐서 워드클라우드로 만드는 라이브러리 만들기 # 워드클라우드 : 텍스트 데이터를 시각적으로 표현 stopwords = set(STOPWORDS) # set 집합을 사용해 불(Bool)용어 지정 # 불용어 집합을 STOPWORDS 변수에 할당 wc = WordCloud(font_path="c:\WINDOWS\Fonts\H2GTRM.TTF", stopwords=stopwords) # 워드클라우드 객체 생성 wc.generate(str(news_title_lists)) # 워드클라우드 객체인 wc를 사용해 텍스트 데이터인 new_title_lists를 분석하고, # str(news_title_lists)는 리스트를 문자열로 변환하는 코드 wc.to_file('wordcloud_bm.png') # 워드클라우드 이미지로 저장 if __name__ == "__main__": xl() input()
위 코드를 실행하면 인터넷이 열리고 단어를 자동 검색 후, 그 결과를 텍스트 데이터로 가져옴.
이를 바탕으로 워드클라우드와 엑셀을 만들어냄.
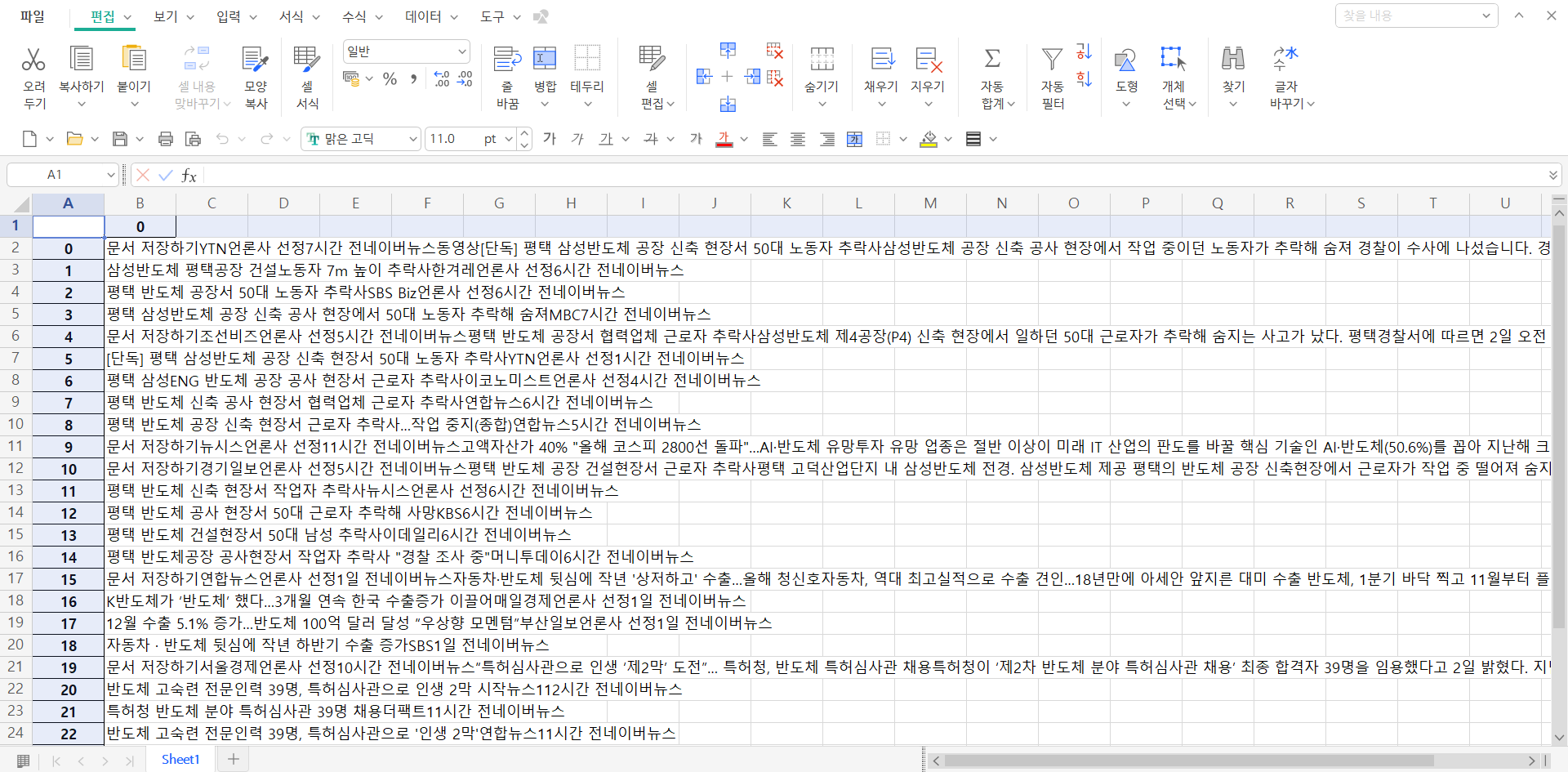
만들어진 엑셀 
만들어진 워드클라우드
df = pd.DataFrame(news_title_lists) # news_title_lists에 있는 데이터들을 pandas 데이터프레임으로 저장데이터프레임은 데이터를 표 형태로 처리할 수 있도록 만드는 구조
'PYTHON > Python 업무 자동화' 카테고리의 다른 글
HTML의 코드 구조와 요소 (Element), Selenium 기본 문법 (0) 2024.01.06